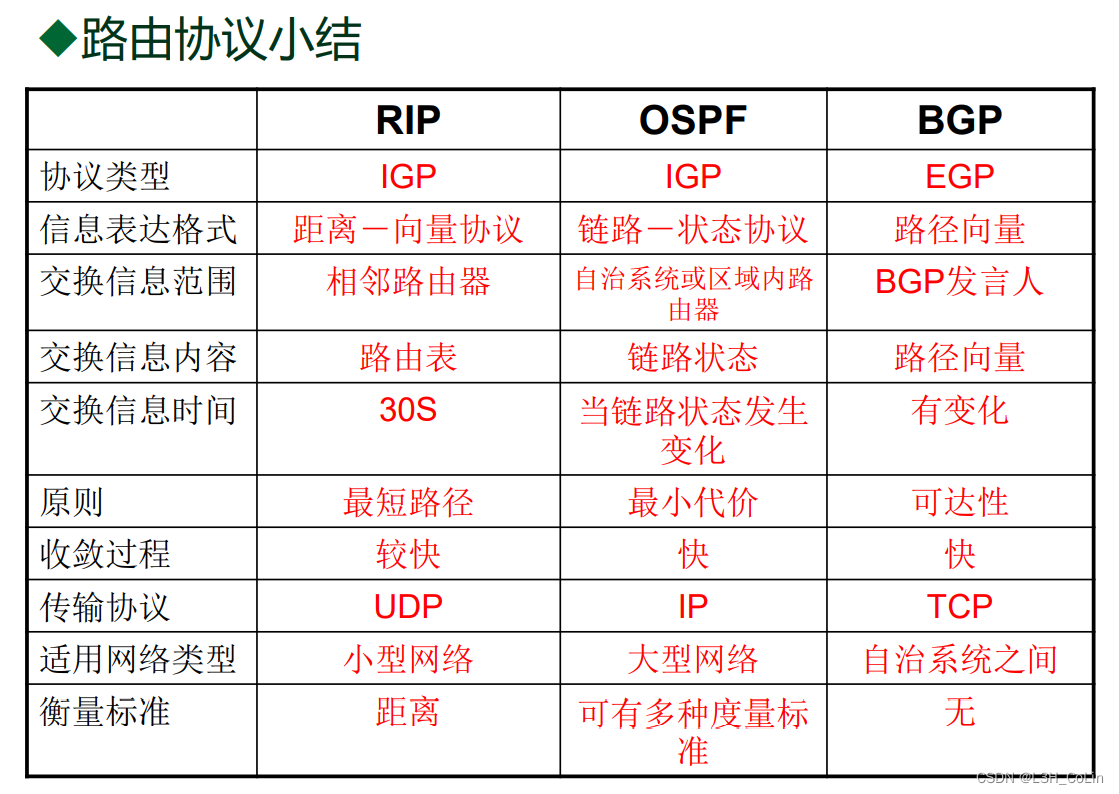
4.1 存储器概述
存储器可以分为:
- 随机存储器RAM,按照地址随机读写数据存储单元,且存取访问时间与存储单元的位置无关。
- 顺序存储器SAM,存储单元中的内容只能按照顺序访问,且访问速度与存储单元的位置有关。
- 直接存储器DAM,不必经过顺序搜索就能够在存储器中直接存取信息的存储器,兼有随机存储器和顺序存储器的访问特性。
- 只读存储器ROM。
存储系统的层次结构
现实世界中,一个存储器的存储速度、存储容量和成本往往是相互矛盾的,因此需要多种不同类型的存储器。典型的存储系统是一个金字塔结构,从上到下依次为寄存器、高速缓存、主存、磁带、磁盘等。越往上访问速度越快,单位容量的成本越高,越往下存储容量越大。
存储体系层次化结构的理论基础:时间局部性原理和空间局部性原理。
主存中数据的存放
- 存储字长:主存的一个存储单元能够存储的二进制位数。
- 数据字长:计算机一次能处理的二进制数的位数。
- 数据的边界对齐:在数据对齐的情况下,访问主存的次数相对于不对齐会减少一些,虽然浪费了一些空间,但是能够提升速度。以32位系统为例,双字数据的地址应该以8为倍数对齐,字数据地址应该以4为倍数对齐,以此类推。
- 大小端存储:采用多字节方式访问主存时主存中的字节顺序。存储器的低字节单元中存放的是数据的高字节时,称为大端,反之称为小端。
4.2 半导体存储器
4.2.1 静态MOS存储器
存储器以静态MOS存储元为基本单元构成的存储器称为静态MOS存储器(SRAM)。
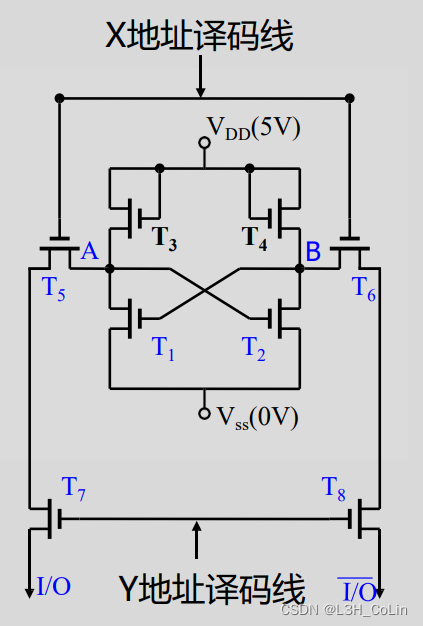
工作原理
- 要想获取该单元存储的数据是0还是1,需要看A点和B点的电位。当A点为高电平而B点为低电平时,存储1,反之存储0。当A点为高电位时,T2导通,T1断路。
- T3和T4为补充电荷使用。无论A还是B为高电平,这两个三极管一定导通,当A为高电平时,B接地,因此从T4过来的电荷都漏掉了,B点的电压还是0V,而A点则可以维持高电平。反之同理。
- 读取:当X地址译码线与Y地址译码线均导通时,4个三极管均导通,A的电平输出到左边,B的电平输出到右边。
- 写入:两个地址线导通后左边与右边一个输入高电平,一个输入低电平。设原来单元中存储1,现需要将其写为0,则需要向左边输入0V,右边输入高电平,这样放走了左边A的电荷之后,右边的T2就断路,B不再接地,其电荷量增加,导通T1使A的电荷完全被导走,以此达到新的稳态。注意这其中的步骤顺序。
单译码结构:一维的线性结构,索引一个存储单元只需要一个地址线。索引2n地址空间需要2n条地址线。
双译码结构:二维的地址结构,索引一个单元需要两个地址线。索引2n地址空间需要2n/2+1条地址线。
4.2.2 动态MOS存储器
SRAM的不足之处有:晶体管数量较多,存储密度低,功耗大。
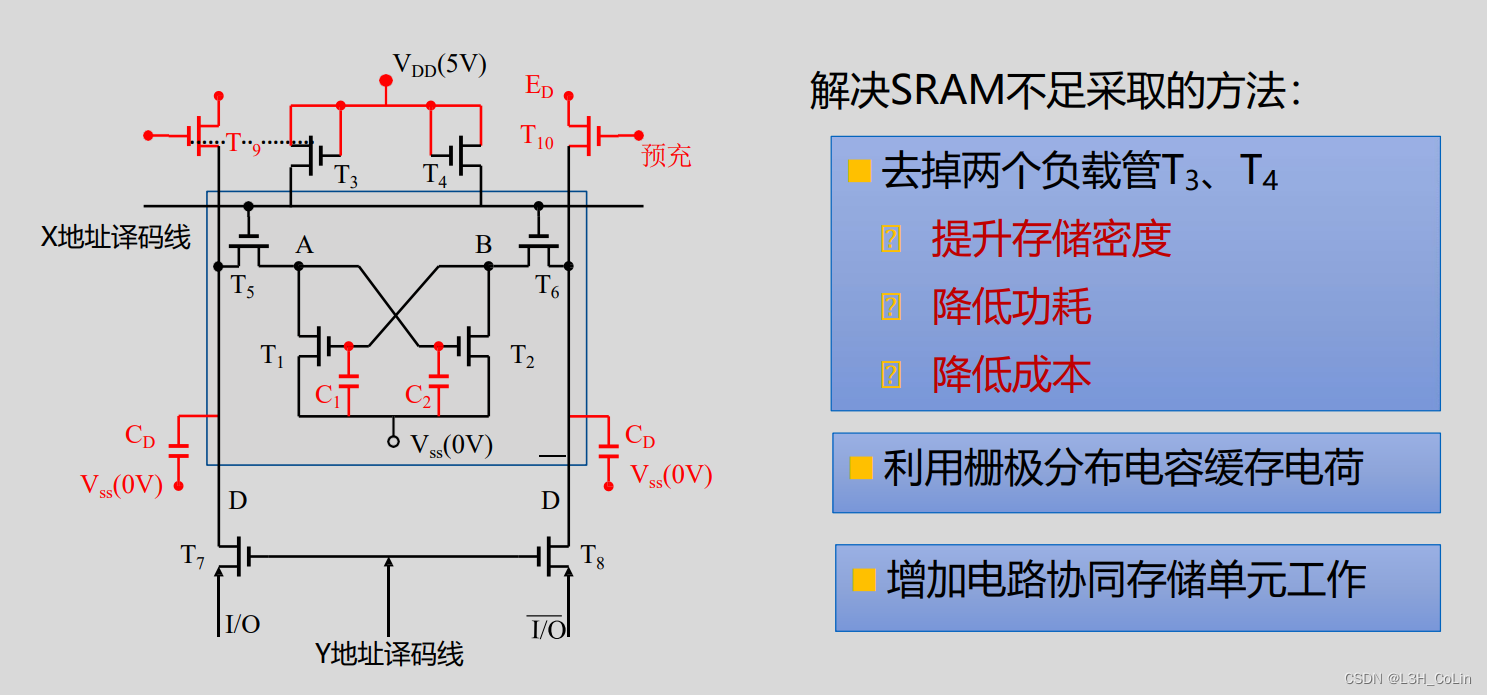
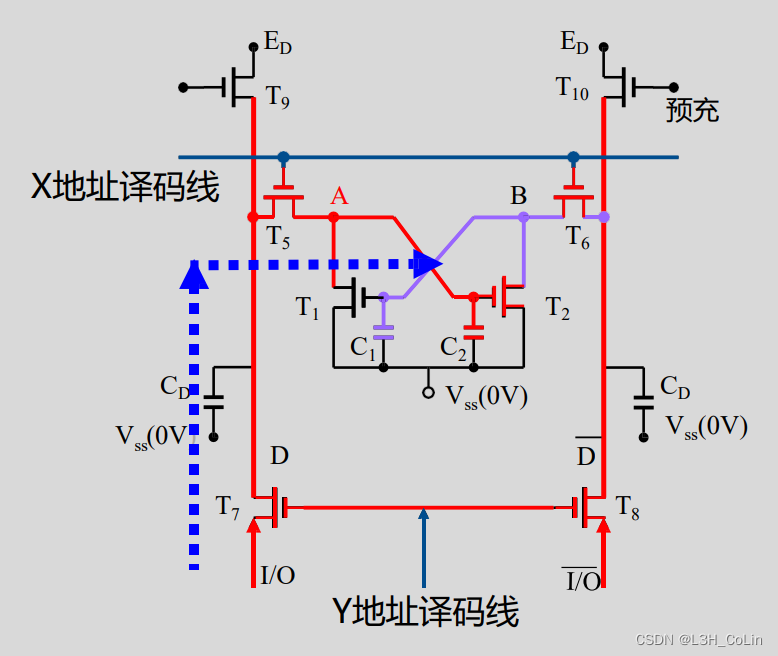
工作原理
- 处于保持状态时,预充、两条译码线均为低电平,若此时A为高电平,B为低电平,则B接地,A上有大量电荷,因此电容C2带电,可以让A的高电平状态维持一段时间,但电荷还是会有流失,因此保持状态如果时间过长,其中的数据就会丢失。
- 刷新状态:预充和一条译码线(X译码线)导通,进行充电。如果原来A上带有电荷,但由于泄露已经较为微弱。在导通X译码线和预充之后,A得到了直接的电荷补充,而B由于此时仍然接地,因此无法得到电荷。双地址结构的DRAM刷新是按行进行的。
- 读数据:首先导通预充信号充电,使得左右两个CD充满电。若此时A为高电平,充电完成后先导通X地址译码线,这样左边CD会为C2充电,自身电荷量增加,而右边的CD将电荷部分转移到C1中,自身电荷量减少。然后导通Y地址译码线,左边输出的电平略高于VCC/2,右边输出的电平略低于VCC/2。
- 写数据:首先导通Y地址译码线,并写入高电平和低电平,设向原来保存1的单元写入数据0,则右边输入高电平,左边输入低电平,因此右边CD带电荷。然后导通X地址译码线。先是C2上的电荷量大量减少,使得B不再接地,然后B接收到右边CD的电荷,让A接地。
DRAM的刷新
- 最大刷新周期:信息存储到丢失之前的这段时间,两次刷新时间间隔不能超过最大刷新周期。
- 刷新周期:存储器实际上完成两次刷新的之间的时间间隔。
- DRAM按行进行刷新,为减少刷新的周期,可以减少存储矩阵行数,增加列数。
- 读操作也有刷新功能,但只能刷新一个单元。
刷新的不同方式:
- 集中刷新:将所有行在连续的一段时间内全部刷新完成。设刷新周期为2ms,2ms内一共可以进行4000次读写与保持操作,DRAM共256行,则集中刷新法是在前3744个读写周期内进行读写,而在后256个读写周期进行每一行的刷新。优点:读写操作期间不受刷新操作的影响,速度较快。缺点:存在较长时间无法进行访问的情况,“死区”。
- 分散刷新:将存储周期(时间较短,1μs左右)分为两个部分,第一个部分用于读写,第二个部分用于刷新。优点:不存在死区。缺点:速度慢。
- 异步刷新:将所有行的刷新平均分配到刷新周期之内,如刷新周期为2ms,共有256行,则将刷新周期分为256等份,每一个等份的前面所有存储周期用于读写,最后的一个存储周期用于刷新。
4.3 主存的组织和CPU的连接
4.3.2 存储器的扩展
- 位扩展:又称为字长扩展或数据总线扩展,将所有存储芯片的地址线、读写控制线并联,将输出合并得到数据内容,可以理解为,如果一块芯片的一个单元只能保存一位信息,则第一块芯片只保存所有地址中的第一位信息,第二块芯片只保存所有地址的第二位信息,等等。
- 字扩展:又称容量扩展或地址总线扩展,其不会增加数据的位宽,每一次寻址只会访问一块芯片,其他芯片没有被访问,输出也只是接受一个芯片的输出。将扩展出来的数据位线(地址的高位)连接到译码器来确定访问哪一块存储芯片。
- 字位同时扩展:上面两种方式的结合。
4.5 高速缓冲存储器
cache:在CPU与主存之间添加一块小容量的快速的SRAM,以提升访问主存的性能。依据的原理是空间局部性。
4.5.3 cache的基本原理
CPU通过字节地址访问快速的cache,首先需要确定需要访问的数据是否在cache中。
- 数据命中:数据在cache中。
- 命中访问时间:当数据命中时数据的访问时间,包括查找时间和cache访问时间两部分。
- 数据缺失:需要访问的数据不在cache中。需要将缺失的数据从主存调入到cache中才能访问数据。
- 缺失补偿:数据缺失时的访问时间,包括数据查找时间、主存访问时间、cache访问时间。
- 命中率:所有访问中成功命中的次数占总访问次数的比例。
- 缺失率:1-命中率。
- 访问效率:cache的命中访问时间与cache/主存系统的平均访问时间的比值。
4.5.4 cache读、写流程与关键技术
读
读入时查找cache中是否有需要读取的数据,有则读取,没有则调入这一块数据后再读取。
写
写比读复杂一些。
首先查找目标地址处的数据是否保存在cache,如果有则写入数据到cache。这里有两种策略:写回策略和写穿策略,写回策略在将数据写入cache之后立即结束操作,会导致cache与主存中数据的不一致;写穿策略在cache中数据被修改后再将数据写入到主存中,速度较慢。
如果目标地址处的数据不在cache,则也有两种选择:一种是将数据直接写入到主存,另一种是将这一块地址的内容载入到cache后写入到cache,至于之后是否需要写入主存使用的就是写回策略和写穿策略两种策略了。
4.5.5 相联存储器
相联存储器可用于判断对应地址的数据是否保存在该存储器中,基本数单元是键值对,键是主存地址,值是主存地址下的数据。由于相联存储器可以进行所有键值对的并行查找,因此只需查找一次就可以确定一个键值对。
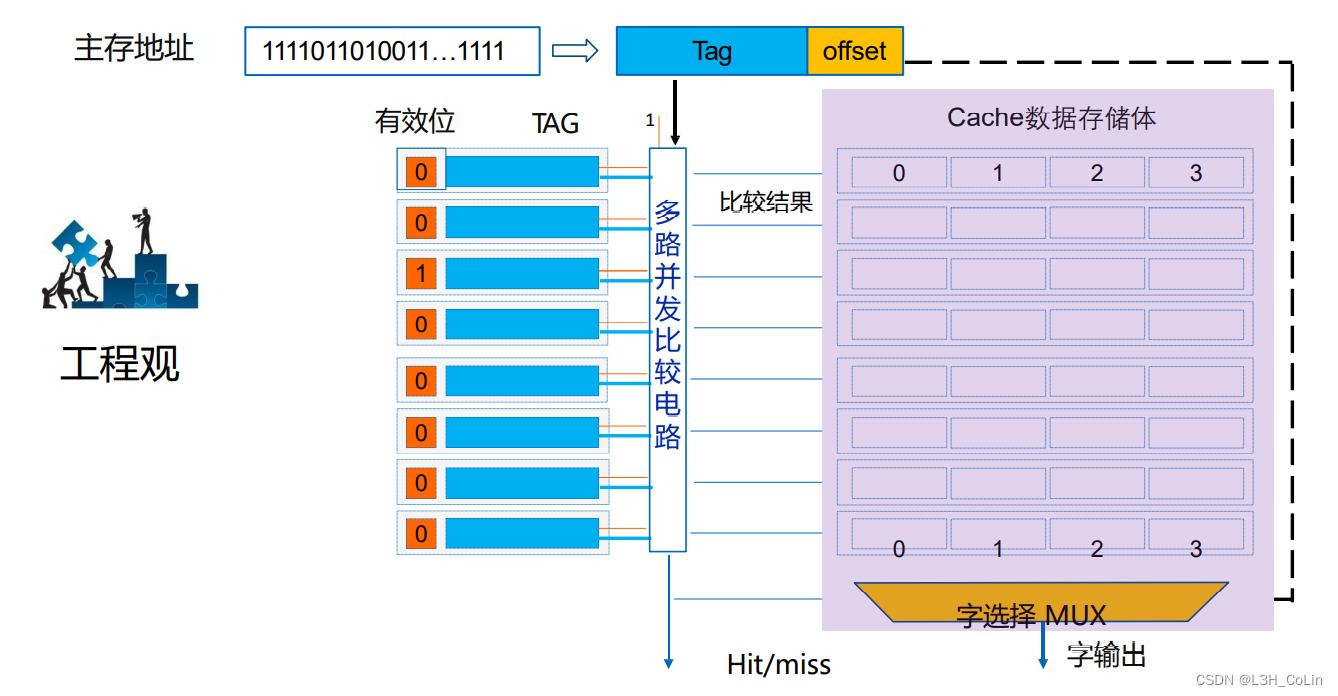
4.5.6 地址映射
地址映射即为将主存地址空间映射到cache的地址空间,将存放在主存的程序或数据载入到cache块的规则。
- 全相联:各个主存块都可以映射到cache中的任意一个数据块。
- 直接相联:各个主存块只能映射到cache的固定某一块。
- 组相联:各个主存块只能映射到cache固定组中的任意块。
全相联映射
主存中每一个数据块都可以放置到cache中的任意一个数据块中,是一对多的映射关系。新的数据块可以载入到cache中任意一个空闲位置,只有cache满时才会进行数据块置换。
在全相联映射中,主存地址被划分为两部分:块号和块内地址。如果一块的大小为1024字节,则块内地址共10位,高位为块号。在cache中会保存块号和主存中该块号下的数据内容。
优点:cache利用率高,块冲突率低。缺点:淘汰算法复杂。适用于小容量的cache。
直接相联映射
在直接相联映射中,主存地址分为三部分:区号、区内块号、块内地址。其中区内块号为x,cache行数为y,则该块在cache中应该保存在第x行的位置。区内块号表示的数值应该与cache中的行数相同。
优点:淘汰算法简单。缺点:利用率较低,块冲突率高。使用率大容量cache。
组相联映射
组相联映射将主存地址分为3部分:组号、组内块号、块内地址。cache中所有行分为若干组,设一组有m行,共n组,则主存地址组号为x时应该保存在cache中的第x mod n组,组内块号为y的地址处应该保存在cache中的保存该组号的组中的任意一行。
4.5.7 替换算法
- 先进先出算法
- 最不经常使用算法:替换访问次数最少的cache
- 近期最少使用算法:为每一行维持一个计数器,命中时计数器清零,否则加1,将计数器最大的行换出。
- 随机替换算法
4.6 虚拟存储器
虚拟存储器处于主存-辅存存储层次,为了解决主存容量不足的问题,为程序设计者提供比主存空间大的编程空间。
虚拟存储器可以分为:页式、段式和段页式。
三种地址空间:虚拟地址空间、主存的地址空间、辅存地址空间。
在虚拟存储系统中运行时,CPU以虚拟地址访问主存,使用存储管理部件MMU找到虚拟地址与物理地址的对应关系,并判断该虚拟地址对应的物理地址是否在主存中,如果在则将虚拟地址转化为物理地址,CPU直接访问主存单元;否则将包含这个字的一页或一段调入主存,并在MMU中填写相关的标记信息。
4.6.3 页式虚拟存储器
虚拟地址被划分为虚拟页号VPN和虚拟页偏移VPO两部分,同时物理地址按照相同的划分方式分为物理页号PPN(页框号)和物理页偏移PPO。
页面命中时CPU硬件执行的步骤:
- CPU将虚拟地址传送给MMU。
- MMU用页表基址寄存器PTBR和虚页号生成页表项地址PTEA,通过这个页表项地址可以找到目标虚拟地址对应的物理地址值保存在什么位置。
- cache或主存向MMU返回页表项PTE。
- 如果返回的PTE中有效位为1,则MMU利用返回的PTE构造物理地址PA,并利用构造出的物理地址PA访问cache或主存。
- cache或主存返回数据给CPU。
缺页处理流程:前3步与上面相同
- PTE中有效位为0,所访问的页不在主存中,MMU触发异常调用内核的缺页中断处理程序。
- 如果主存页满,需要根据算法确定换出哪一个页,如果换出的页的有效位为1,则需要将其换出到磁盘。
- 缺页中断处理程序从磁盘中调入新的页,更新存储器中的页表项PTE。
- 返回原来进行继续执行。
如果存储系统中包含cache,则可以将部分页表的内容保存到cache中。
转换旁路缓冲区:TLB,用于缓冲经常访问的页表项PTE,实质是一个小容量的cache,大多采用全相联或组相联形式以提高访问速度,且采用随机替换算法。通常称TLB中保存的表为快表,主存中保存的表称为慢表。